Ya sea un medio de comunicación, un e-commerce o cualquier otro site de gran envergadura, su enorme cantidad de páginas o URLs nos va a obligar, antes o después, a echar un vistazo a cómo se organiza, se engloba y se presenta el contenido al usuario por medio de sus diferentes secciones o categorías.
Este análisis nos dará información muy útil de cara a conocer qué secciones son las más fuertes a nivel SEO, cuáles tienen potencial y merecen ser trabajadas más en profundidad y cuáles, simplemente, no funcionan y, por lo tanto, es mejor abandonarlas para poner los esfuerzos en otra parte que sí merezca la pena.
A estas alturas, ya sabemos qué significa el presupuesto de rastreo o crawl budget en SEO, y en sitios con tantas URLs resulta crucial no hacer perder el tiempo a Google rastreando secciones o categorías que no están funcionando, y sí aquéllas que más resultados y beneficios nos están dando. En este post veremos cómo tener una visión global de un site grande, a través del análisis de sus secciones, que nos permita tomar las decisiones de arquitectura de la información más adecuadas. Y lo que es más importante: que esas decisiones sean seguras, firmes y sabedoras del impacto que tal o cual cambio pueda tener en el SEO del site.
Funcionamiento
Rastreo
Lo primero de todo es crawlear o rastrear el sitio web en cuestión. Dependiendo de la herramienta que utilicemos para ello, necesitaremos hacer algunas configuraciones previas. Por ejemplo, si utilizamos Oncrawl, separar las URLs que corresponden a las diferentes secciones o paths va a ser mucho más sencillo, pero si utilizamos Screaming Frog, vamos a tener que rastrear las secciones o directorios por separado, ya que si lo rastreamos todo de una sola vez, en lugar de hacerlo por partes, lo más probable es que vaya a durar días. Y no sólo eso: el ordenador nos irá muy lento mientras tanto por el gran consumo de memoria RAM que va a requerir (aunque podemos decirle que consuma menos, pero esto también provocará que el rastreo tarde más). Por ello, si vamos a utilizar Screaming Frog, lo más inteligente sería rastrear las secciones por separado. Una idea de configuración para que sólo rastree una sección, directorio o path (llamémosle como se quiera) específico es ésta, dentro de Configuration à Include:
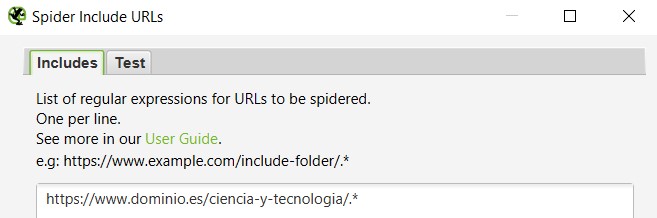
Con esto le estamos diciendo a la herramienta que sólo nos incluya en el rastreo el directorio de Ciencia y tecnología. Si lo que queremos es rastrear un subdirectorio que cuelgue de este directorio principal -por ejemplo, sólo el de Ciencia-, la operación es la misma:
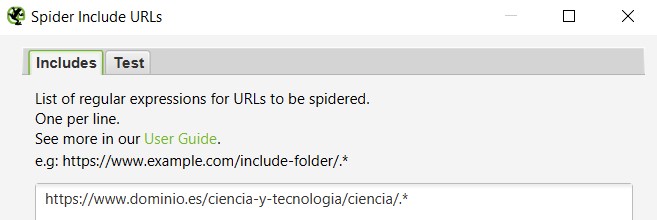
Recuento
Adicionalmente, para el análisis de arquitectura de la información, nos va a venir bien saber cuántas palabras hay en el cuerpo de la URL o del artículo. Aunque es cierto que Screaming Frog ya tiene una columna dedicada a ello (Word Count), ésta no es del todo fiable, pues en ella cuenta también las palabras que puedan aparecer en módulos de artículos relacionados y widgets en general, y ya sabemos que eso, a ojos de Google, puede ser contenido común, y lo que le interesa al robot de Google es el contenido único y específico del cuerpo de la página. Por ello, antes de lanzar el crawl, a la configuración anterior deberemos añadirle otra: un Custom extraction (Configuration à Custom à Extraction). Deberemos identificar cuál es el CSSPath del cuerpo de la página y añadirlo aquí, especificando que lo que queremos es que nos extraiga el texto:

Si vamos a analizar un medio de comunicación, también puede ser interesante hacer un Custom Extraction para sacar la fecha de publicación de las noticias y el autor con el objetivo de ver si tal o cual sección está predominada por artículos muy antiguos, en cuyo caso habrá que reforzar actualizándolos o escribiendo nuevos y actuales; y detectar qué artículos no vienen firmados, y los que sí, por quién, de manera que podamos tener un mayor control sobre cómo lo estamos haciendo de cara a todo el tema de E.A.T., que cada vez está dando más importancia Google:

En la imagen de arriba, estaríamos extrayendo el autor, la fecha e incluso la hora de publicación de un artículo o noticia, por medio del XPath.
Análisis
Una vez tenemos todo esto configurado, lanzamos el crawl y, una vez terminado, exportamos en un excel todas las URLs de la sección/es específicas que hayamos rastreado. El siguiente paso sería cruzar datos que nos proporcionan otras herramientas y que nos van a permitir conocer la salud, el potencial y el poderío (o no) SEO de esas secciones. Como estamos hablando de secciones y no de URLs, este cruce de datos no debería llevarnos mucho tiempo, ya que, por lo general, un site no cuenta con excesivas secciones:
- Índice de visibilidad, a poder ser Mobile: Esto nos los proporciona la herramienta Sistrix.
- Keywords posicionadas en el top 10 y en el top 100: También nos lo proporciona Sistrix.
- Clics orgánicos: Search Console nos da este dato. Lo óptimo es seleccionar un tiempo lo suficientemente amplio, por ejemplo, un año.
- Dominios de referencia: Podemos sacarlos de Ahrefs, por ejemplo.
En un excel podemos recoger todos estos datos e ir haciéndonos una idea del potencial SEO de una sección u otra:
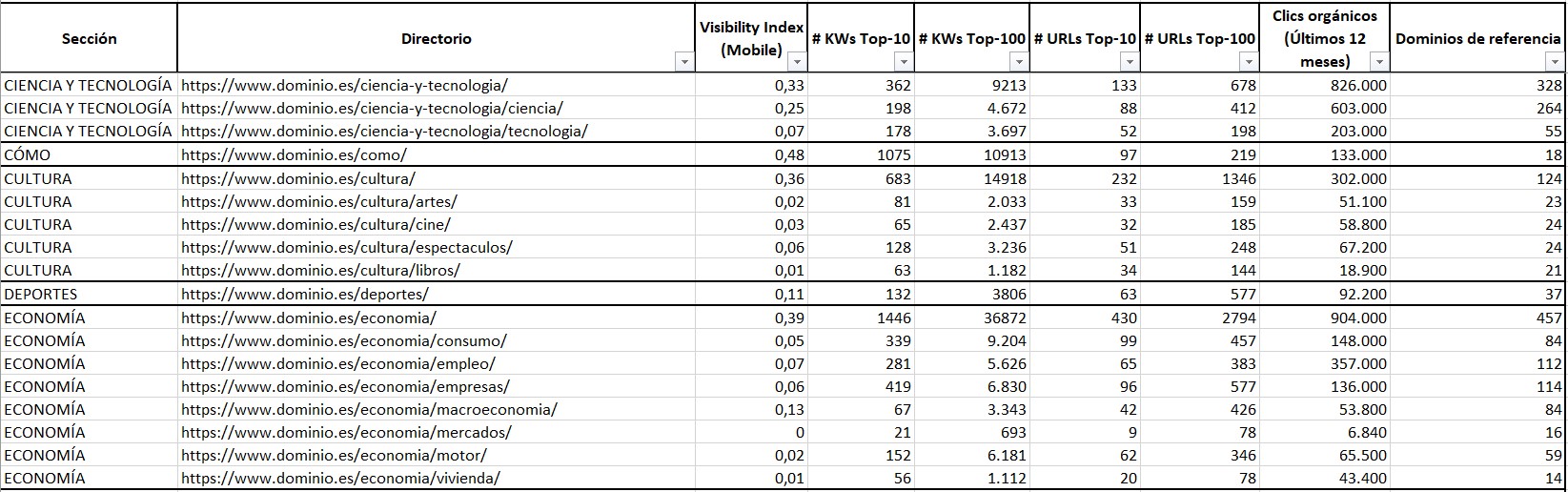
Si utilizamos Oncrawl, debéis saber que la herramienta cuenta con un conector –Data Ingestion– que nos permite inyectar a través de CSV datos de otras herramientas (https://help.oncrawl.com/en/articles/2536081-data-ingestion-with-csv-files), de modo que podemos matchear los datos del crawl con los datos anteriormente citados (índice de visibilidad, keywords posicionadas, dominios de referencia…). De esta forma, podemos tener todos los datos juntos.
Utilidad
Ahora es hora de sacar provecho de los crawls que hemos lanzado antes. En otra hoja de excel (o en la misma, como se prefiera), vamos a incluir los siguientes datos, separados por secciones o directorios:
- URLs rastreables: Todas las URLs a las que ha podido llegar la herramienta de crawling y, por lo tanto, a las que también puede llegar Googlebot.
- URLs indexables: URLs susceptibles de ser indexadas en el buscador.
- % indexable: Para ver de un simple vistazo si una sección tiene problemas de indexación o no.
- Artículos sin categorizar: URLs que cuelgan directamente del directorio o sección (por ejemplo, /cultura/) en lugar de un subdirectorio o subsección (/cultura/cine/ o /cultura/libros/). Esto es interesante analizarlo porque si existen muchas URLs en esta situación, estamos perdiendo la oportunidad de nutrir y fortalecer el SEO de otras subsecciones con URLs que encajarían mejor aquí que en la sección general.
- Promedio palabras por artículo: Una media del número de palabras que se encuentran exactamente en el body o cuerpo del artículo, y que hemos extraído durante el crawl.
- Promedio año de los artículos: Como decíamos anteriormente, para ver si una sección o directorio necesita ser empujado o no a la hora de actualizar su contenido o nutrirlo con nuevo.
- Acción propuesta: Como su nombre indica, qué proponemos hacer con la sección/directorio/subdirectorio en cuestión.
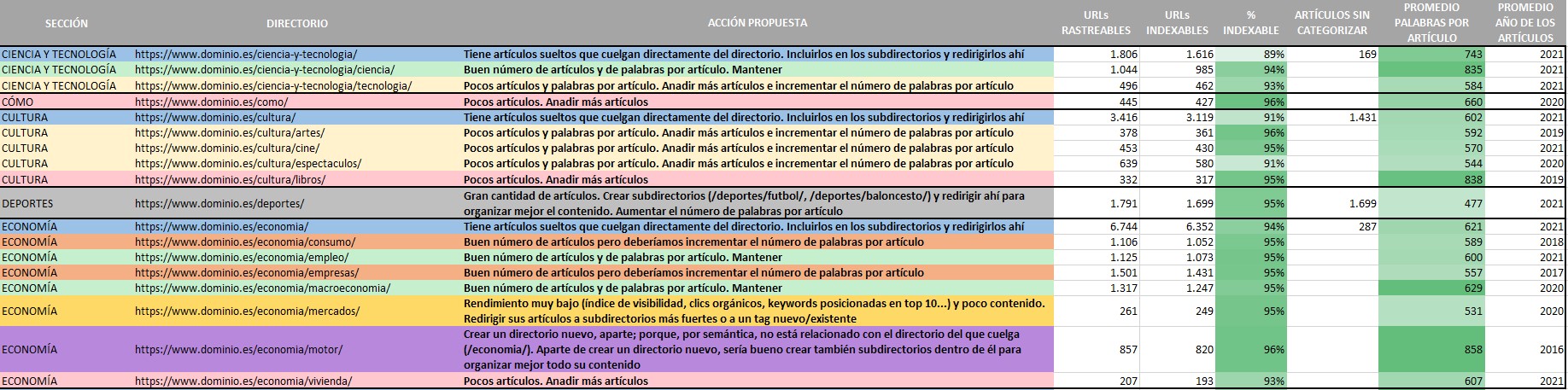
Con todos estos datos, podemos forjar una toma de decisiones sólida a la hora de determinar qué hacemos con una sección o un directorio determinado -añadir más artículos/URLs, más palabras por artículo/URL, redirigir los contenidos o URLs de una sección a otra que sea afín con la idea de fusionarlos en una sola, crear nuevos subdirectorios a partir de directorios y redirigir sus contenidos/URLs a esos subdirectorios para organizar mejor el contenido, crear directorios o secciones nuevas, mantener una sección/directorio/subdirectorio porque tiene un % de indexabilidad alto, un índice de visibilidad alto, muchos clics orgánicos, posiciona por muchas keywords en el top 10, es enlazado por muchos dominios externos, goza de bastantes palabras por URL de media y, además, sus contenidos son actuales y no se han quedado anticuados, etc.-.
Los colores nos ayudan a categorizar esas decisiones. Apoyándonos en una especie de leyenda, podemos establecer más fácilmente las acciones a llevar a cabo en cada sección, directorio o subdirectorio del sitio web. De cada cual depende añadir más casuísticas (colores) o menos. Aquí os dejamos un ejemplo que engloba unas cuantas acciones:

Conclusión
Como veis, las posibilidades y las decisiones en cuanto a las acciones a desarrollar son amplias. En este artículo hemos expuesto un ejemplo que puede ser de utilidad a la hora de decidir qué hacer con las secciones de un site de gran envergadura que necesita ser analizado para decidir sobre sus contenidos; si se reorganizan, si se eliminan, si se crean nuevos… Pero lo más importante es que, con los datos en la mano, seamos capaces de estar seguros de que cualquier cambio que hagamos en la arquitectura del site, no sólo no tenga un impacto negativo en el SEO de la web, sino que suponga un impulso que se traduzca en un incremento del tráfico orgánico.
¡No olvides que puedes dejarnos tus impresiones en forma de comentario!





